![]()
![]()
|
**********************
Twenty members of the general public worked remotely from one another in pairs. One member of the pair carried out some simple manipulative tasks as instructed by the other, after which they discussed the merit of the object assembled. Sometimes there was a view of the face and sometimes a view of the room. The work was always visible. Contrary to suggestions in the literature that a view of the face has only marginal benefits, subjective ratings and direct measures of gaze behaviour both demonstrate that the view of the manipulators face was of value in this situation.
The integration of video technology with desktop computers and digital networks has presented new opportunities for supporting interpersonal communication with pictures. Most commonly the picture offered is an image of the face of the person one is communicating with. The assumption is that such a view will facilitate non-verbal communication. Whittaker [3] has argued that the evidence for this assumption is weak, particularly when the video image is of low quality. He goes on to suggest that researchers and designers should consider more seriously two alternative views that have been used less frequently. These are: (i) a view of shared work objects, so called 'video as data', and (ii) a view of the work context of the other person. A view of the work has the function of providing a shared physical context which will be important in many tasks. It permits physical pointing as well as more efficient use of language through anaphor and deixis (e.g., 'that one there'). A view of the context of the other person makes it possible to see whether they are in a position to talk, e.g., are they on the phone or talking to someone else?
A good example of the use of these alternative views is presented by the Xerox MTV system [1] . In this experimental system users could switch between four views, each provided by a different camera. These included: a view of the work, an in-context view of the whole office and a view of the face of the other person. Six pairs of people used this system to perform a sketching task and a design task. The view of the face was used least and the view of the work most. The informal observations of these authors were that the different views were used for different purposes. The in-context view of the office was used to determine the remote partner's current orientation, the face view for conversation and so on.
In the experiment described here participants were provided with two views continuously on two monitors rather than switching between them with a rotary switch, as in the MTV experiments. In addition, the distinction between the different purposes to which a view could be put was operationalised by having two components to the experimental tasks. In the first, the collaboration was focused on assembling a toy. Here, one would expect a view of the work to dominate the participants' attention. In the second they were to jointly discuss the merits of the toy for young children. This discussion task was expected to place a greater emphasis on the view of the other person. In this way one can provide some quantitative data about the utility of different views for different purposes.
 FIGURE 1.
FIGURE 1.
Twenty members of the general public were recruited as they visited a science exhibition at a city centre location. They worked as pairs. Their ages ranged from 10 to 65 and they had a wide variety of backgrounds. There were two parts to the experimental session. In each part the pair assembled and then discussed a different children's toy. The same member of the pair, the 'Instructor', was given instructions for assembling the toy. The other person, the 'Manipulator', was taken to an adjacent room (see Figure 1.) They had the components of the toy to be assembled. The pair performed the assembly and discussion tasks for each toy using a different configuration of video link. Half the pairs experienced the two configurations in one order and half in the other order. The equipment used is depicted in Figure 1. Each configuration consisted of a work view and one of two possible 'personal views'.
Manipulator: Direct view of own hands and the toy, video image of the Instructor's head and shoulders.
Manipulator: Direct view of their own hands and the toy, video image of Instructor together with their immediate surroundings as above.
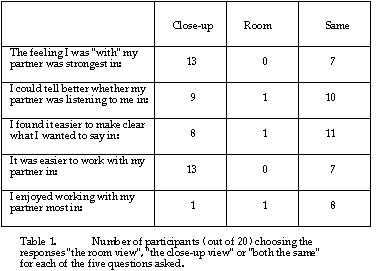 TABLE 1.
TABLE 1.
At the end of the session participants were asked to choose between, 'close-up' (face), 'room'(in-context), or 'both the same', on the basis of 5 criteria. The results are given in Table 1. In all cases there were significantly more 'close-up' responses than 'room' responses (p <.05, 2-tailed binomial tests). The order in which they experienced the two configurations did not significantly affect the proportion of people choosing 'close-up' except in the case of the last question, where more people chose it when it was the condition experienced first (p = .035, Fisher's exact probability test), nor were there any significant differences in the responses of Instructors and Manipulators.
The average session lasted for 15 minutes of which only 3.36 minutes were spent with the second toy. This was probably due in part to this being an easier assembly task and in part because this was the second assembly and discussion task they had attempted. Because the small amount of data available for the second toy and to simplify this account, gaze focus is only reported for assembly and discussion of the first toy. The video records were scored by raters, who did not know which video configuration was being used, using the Action Recorder tool [2] . The proportion of time each participant spent looking towards the view of the other participant as opposed to the work or instructions was computed. The resulting proportions were entered into a three-way split-plot analysis of variance. The sampling unit is the pair. The within pairs independent variables are: task (assembly or discussion) and role (instructor or manipulator). Order (in-context then face, or face then in-context) was the between pairs independent variable.
These gaze data are sensitive to task and view but not role. Neither the role main effect nor any of its interactions with the other variable approached significance. The order (F(1,8) = 10.95, p = .011) and task (F(1,8) = 19.08, p = .002) main effect and the task by role interaction were significant (F(1,8) = 7.96, p = .022). This interaction is plotted in Table 2. The proportion of time spent looking towards the image of the other person was small whatever the view in the assembly task, in the discussion task, however, a much larger proportion was recorded, but only when the view was of the face rather than in-context.
 TABLE 2.
TABLE 2.
the general public to this kind of communication technology. Without exception, they were able to use it effectively to complete the tasks set them. Face and in-context views were compared as an adjunct to a work view. Previous investigators have cast doubt on the utility of a face view. On this basis, one might have expected there to be no difference between the face view and a plausible control. However, there was a strong preference for the face view and the analysis of gaze behaviour shows that this view was used extensively during the discussion though not for assembly. In general, it is clear that the utility of a particular view in video communication will depend crucially on the tasks to be performed and the other views available at the same time.
1. Gaver, W., Sellen, A., Heath, C. and Luff, P. One is Not Enough: Multiple Views in a Media Space. In Proceedings of ACM INTERCHI'93 Conference on Human Factors in Computing Systems, 1993, pp. 335-341.
2. Watts, L.A. and Monk, A.F. Interpersonal awareness and synchronisation: assessing the value of communication technologies. International Journal of Human-Computer Studies, (In press).
3. Whittaker, S. Rethinking video as a technology for interpersonal communications: theory and design implications. International Journal of Human-Computer Studies, 42, (1995), pp. 501-529.
This work was supported by the UK JCI in Cognitive Science and HCI, and ESRC, Cognitive Engineering Initiative. We would like to thank Owen Daly-Jones, Sarah Edwards and Caroline Gale for their help running and scoring the experiment.